Large Language Models (LLMs) are a powerful tool for generating text. They are used to help us study, code, come up with new recipes, and more. However, they are prone to hallucinations; they can generate text that is not factual or relevant to the prompt. Retrieval Augmented Generation (RAG) is a technique that can address this issue by retrieving factual information from external databases. In this article, I will review the main concepts of LLMs and introduce RAG as a way to generate responses based on your own private data.
Foundations of NLP
How do machines understand text? They surely do not understand language in the same way that we do, but they seem to do a pretty convincing job at generating useful output. Focusing on this question will be the theme of this brief overview of Natural Language Processing (NLP), specifically related to Large Language Models.
Tokenization
Tokenization is the process of transforming input text into smaller chunks called tokens. These tokens can be characters, words, phrases, or even whole sentences. The tokens themselves are then represented as numbers in a dictionary. This allows models to move back and forth between the actual text and the tokens they read and generate.
Types of Tokens
- Word Tokenization: Divides text into individual words. It is commonly used for tasks like text classification or sentiment analysis.
- Sentence Tokenization: Splits text into sentences, useful for analyzing document structure.
- Subword Tokenization: Breaks words into smaller units like prefixes or suffixes, which is helpful for handling out-of-vocabulary words.
- Character Tokenization: Segments text into individual characters, beneficial for languages without clear word boundaries.

Figure 1: An example of tokenization using the tokenizer used in gpt-4o.
Tokenizers are trained on a large corpus of data. Frequent subwords or character pairs are identified and merged to create unique tokens. The result is a vocabulary that is tailored for that specific corpus of data, implying that the selection of input documents for training is crucial. For example, a tokenizer trained on legal documents may not be the most efficient choice for a model that works primarily with medical documents.
The choice of tokenizer is dependent on more than just the task. There are also language considerations. For a live demonstration of tokenization, check out tiktokenizer.
Embeddings
With a tokenizer at hand, the next step is to analyze the tokens and learn from them. Specifically, relationships between the tokens are learned through embeddings. Embeddings are numerical representations of tokens that capture the semantic meaning of the text. They are essential for training models to understand and generate text.
Embeddings are learned during the training process of a model, where the model aims to capture the semantic relationships and contextual nuances of tokens. For those familiar with gradient descent, embeddings are optimized to minimize the loss function of the model. This loss function effectively drives the model to learn the best possible embeddings for the task at hand.
Once the embeddings are learned, the embedding layer can then be used to transform our input into a high-dimensional vector space in which the model can operate. This further allows the model to make predictions based on the relationships between the tokens.
Architecture of Language Models
Encoders and Decoders
Language models consist of an encoder, a decoder, or sometimes both. The exact architecture is dependent on the task. Understand the roles that each one plays makes it easier to determine which model is best suited for a given task.
An encoder takes a sequence of input vectors based on the tokens and transforms them into fixed-length representations. Their primary goal is to extract relevant information from the input text. This information is then used in some downstream task such as classification or translation.
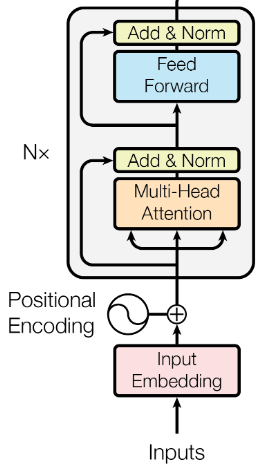
Figure 2: A transformer-based encoder (Vaswani et al. 2017).
A decoder takes the fixed length representation and generates an output sequence. Decoders are commonly used in tasks like machine translation or text generation. They take the information extracted by the encoder and use it to generate the desired output.
The table below summarizes the roles of encoders and decoders in different tasks:
| Task | Encoder Role | Decoder Role |
|---|---|---|
| Text Classification | Extracts relevant information from the input text. | N/A |
| Machine Translation | Transforms the input text into a fixed-length representation. | Generates the output sequence based on the fixed-length representation. |
| Text Generation | N/A | Generates the output sequence based on the input text. |
Transformers
Transformers are a type of neural network architecture that has revolutionized NLP tasks. They are based on the concept of attention mechanisms, which allow the model to focus on different parts of the input text when making predictions. This attention mechanism is what enables transformers to capture long-range dependencies in text, making them particularly effective for tasks like machine translation and text generation (Vaswani et al. 2017).
Attention mechanisms produce relationships between sequences. When we look at an image of a dog running in a field with the intent of figuring out what the dog is doing in the picture, we pay greater attention to the dog and look at contextual cues in the image that might inform us of their task. This is an automatic process which allows us to efficiently process information.
Attention mechanisms follow the same concept. Consider a machine translation task in which a sentence in English is translated to French. Certain words between the input and output will have stronger correlations than others (Bahdanau, Cho, and Bengio 2016).
Training Large Language Models
Since the main focus of this workshop is on Retrieval Augmented Generation, we will focus specifically on decoder-only LLMs like ChatGPT and Claude. These models are trained using a self-supervised learning approach, where the model learns to predict the next token in a sequence based on the previous tokens. This process is repeated over a large corpus of text data, allowing the model to learn the underlying patterns and relationships in the data (Radford et al. 2018).
Training in this way allows the model to train on a virtually unlimited amount of data; the supervisory signals do not require human annotation. The more data the model is trained on, the better it can learn the underlying patterns in the data. This is why LLMs are typically trained on massive datasets like the Common Crawl or Wikipedia.
Advanced Concepts in LLMs
After an LLM is trained, it can be used for many downstream tasks including chat, translation, summarization, and more. However, to make the most of these models, it is essential to understand some advanced concepts in LLMs.
Context Length
The context length of a model refers to the number of tokens that the model can consider when making predictions. This is an important factor in determining the performance of the model on different tasks. A model with a longer context length can capture more information about the input text, allowing it to make more accurate predictions. However, longer context lengths also require more computational resources, making them slower and more expensive to train.
Fine-tuning
Fine-tuning is the process of taking a pre-trained model and training it on a smaller dataset for a specific task. This allows the model to adapt to the specific patterns in the data and improve its performance on the task. Fine-tuning is essential for achieving state-of-the-art performance on many NLP tasks. Consider a law firm that has a large corpus of legal documents. These documents will surely contain legal jargon and specific patterns that are not present in the general text data used to train the model. Fine-tuning the pre-trained model results in a model that is better suited for the legal domain while still benefiting from the general knowledge learned during pre-training.
This is not always a direct upgrade from the original model. Depending on the quality of the dataset, the resulting model may perform worse than it did originally. There are also risks related to data privacy. If the dataset contains confidential information, the LLM may inadvertently memorize this information during fine-tuning.
While fine-tuning may increase the performance on general tasks related to the new domain, it still does not solve the issue of context-specific data. This is where retrieval augmented generation comes into play.
Chat Models
 keynote.](/ox-hugo/2024-10-11_14-06-35_screenshot.png)
Figure 3: From Andrej Karpathy’s State of GPT keynote.
To create a chat model, a pre-trained LLM must be meticulously fine-tuned to behave as a chatbot. This involes three additional steps on top of the original model. This is summarized in the figure above.
Supervised Fine-tuning
The first step is supervised fine-tuning. This involves created a specialized dataset that demonstrates the desired behavior of the chatbot. These samples must be vetted by human annotators to ensure quality. This process is not necessarily training the model to give the most accurate responses, but rather to give the most human-like responses.
Reward Modeling
To optimize the quality of the model’s reponses, we need some way to tell the model what a quality response looks like. In this step, another specialized dataset is created based on a prompt and a number of different responses. A human annotator then assigns a ranking to these responses. This ranking is used as a reward signal for the model to optimize.
The reward model itself is then trained to predict the ranking of the responses based on the human annotations. Once trained, the reward model is used to provide feedback to the chat model during training.
Reinforcement Learning
With a trained reward model, the final stage of training is performed. Given an SFT model and the reward model, reinforcement learning is used to optimize the chat model. A prompt is given to the SFT model, which generates a response. This response is then ranked by the reward model, and the chat model is updated based on the reward signal.
Emergent Capabilities
As it turns out, a model that was pre-trained on a large corpus of text data can be used for more than just generating text. It can also perform downstream tasks like question-answering without explicitly being trained on that task. This is known as zero-shot, or few-shot, learning (Brown et al. 2020).
Given an input prompt, a pre-trained LLM will generate text that is relevant to the text contained within the prompt itself. If the prompt contains specialized context for a specific task, the generated text will also be relevant to that task. For example, provided an example of the task within the context before adding a novel prompt, the model will generate text that is relevant to the task.
Example from (Brown et al. 2020)
Alice was friends with Bob. Alice went to visit her friend ______. -> Bob
George bought some baseball equipment, a ball, a glove, and a _____. ->
Retrieval Augmented Generation
If you have used an LLM such as ChatGPT, Claude, or Gemini, you will have noticed that the responses are not always accurate. This is because the model is generating responses based on the input prompt alone. It does not have access to external information that could help it generate more accurate responses. Recent iterations of these popular models are now incorporating retrieval mechanisms to address this issue.
Retrieval Augmented Generation (RAG) is a technique that retrieves relevent document chunks from external databases that are relevant to the original prompt. These chunks are compared to the context of the prompt primarily through semantic similarity, but other methods can be used as well. The model then generates a response based on the retrieved information. The benefit to this approach is that the model can generate responses that are not only factual, but based on your own private data without requiring any fine-tuning processes.
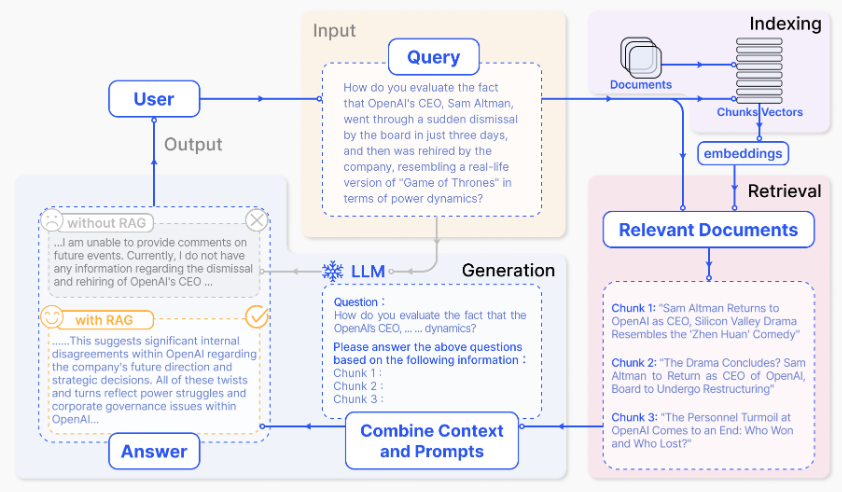
Figure 4: Overview of RAG (Gao et al. 2024).
The basic process is conceptually simple:
- Given a prompt, relevant document chunks are retrieved from a database.
- The retrieved context is used to augment the original prompt.
- The model generates a response based on the augmented prompt.
RAG is an open research area with many potential applications. It is particularly useful in situations where the model needs to generate responses based on specific information that is not present in the training data. For example, a legal chatbot could use RAG to retrieve relevant legal documents to generate responses to legal questions. It can certainly be tricky to implement, but the benefits are clear.
The rest of this article will take a more hands-on approach. See the accompanying repository for a practical demonstration of how to use RAG to talk to your data.