Distributed Databases
Distributed systems excel at partitioning large problems into smaller chunks that can be processed in parallel. This requires parallel thinking instead of serial thinking. Many algorithms and solutions that run serially may be easier to adapt to parallel applications than others.
Distributed solutions are the natural next step to scaling up a system. In the context of databases, the main challenges related to distribution, replication, distributed transactions, distributed metadata management, and distributed query processing.
Overview
According to Elmasri and Navathe (Elmasri and Navathe 2015), a distributed database should satisfy at least the following conditions:
- database nodes should be connected by a network,
- the information on each node should be logically related,
- and each node does not necessarily need to be identicaly in terms of data, hardware, and software.
Transparency
Transparency is the concept of hiding the complex details of a distributed database from the user. There are several types of transparency:
- Distribution transparency - the user does not need to know how the data is distributed across the nodes. This could refer to the location of the data, the replication of the data, or the fragmentation of the data.
- Replication transparency - data may be stored in multiple nodes. This type of transparency improves availability by allowing the system to continue operating even if a node goes down.
- Fragmentation transparency - data is either horizontally or vertically fragmented across nodes. Horizontal fragmentation, also called sharding, refers to decomposing tuples of a table into multiple systems. For example, we could horizontally fragment our
Charactertable based on theclass_id. Vertical fragmentation refers to decomposing the columns of a table into multiple systems. For example, we could vertically fragment ourCharactertable into aCharactertable and aCharacterStatstable.
Availability and Reliability
Having more than one point of failure means that a distributed database is more reliable than a centralized database. With technologies like replication, the availability of the database also increases.
Scalability
Scalability in a database that is distributed over multiple nodes can be categorized into two types:
- Horizontal scalability - adding more nodes to the system.
- Vertical scalability - adding more resources to the nodes.
A centralized database can only support vertical scalability. If it goes down or is fragmented from a portion of a broader network, the data is no longer accessible. In a distributed system, the nodes can be partitioned into smaller networks that can still operate independently depending on the type of failure. This is called partition tolerance.
Autonomy
Autonomy refers to the ability of a node to operate independently of other nodes. This is important for distributed systems because it allows for the system to continue operating even if a node goes down.
- Design autonomy - Data model usage and transaction managament are independent of other nodes.
- Communication autonomy - Nodes can communicate with each other without the need for a central coordinator.
- Execution autonomy - Nodes can execute transactions independently of other nodes. While this type of autonomy leads to more availability and higher performance, it can also create problems with consistency since nodes may not be able to agree on the order of operations.
Data Fragmentation
As mentioned at the beginning of these notes, breaking up a problem into smaller chunks is the key to parallelism. In the context of databases, this means figuring out which nodes have which portions of the data. We will discuss fragmentation under the assumption that no data replication is being used.
Horizontal Fragmentation (Sharding)
Imagine a scenario in which we shard our Users table based on the geographic location of their IP address. If we have 3 nodes in (west coast, central, east coast), then we can separate our table into 3 tables, one for each region. This is called horizontal fragmentation or sharding. The main advantage of sharding is that it allows us to scale horizontally. The main disadvantage is that it makes it more difficult to perform queries that require data from multiple regions.
Vertical Fragmentation
Vertical fragmentation can make sense when we have a table with a large number of columns. For example, we could vertically fragment our Users table into a Users table and a UserStats table. When vertically fragmenting data, there should be a common attribute between the two tables. In this case, the user_id would be the common attribute.
Data Replication
Data replication is the process of storing the same data in multiple nodes. There are obvious tradeoffs when it comes to selecting a replication strategy. First, let’s consider the extreme cases. If no replication is used, then the system is more consistent since there is only one copy of the data. The availability suffers, however, since there is only a single copy of the data.
If the data is replicated to every single node, then the availability and performance of the system increases. However, the consistency of the system suffers since there are multiple copies of the data that need to be kept in sync. Picking a replication strategy will largely depend on the needs of the application. Deciding how this data is fragmented is the process of data distribution.
Example
The following example is from Elmasri and Navathe (Elmasri and Navathe 2015). In this example, a company has three nodes for each of its departments. Node 2 stores data for the Research department and Node 3 stores data for the Administration department. The idea behind this is that the EMPLOYEE and PROJECT information for each department will be frequently accessed by that department. This would be more efficient than having to access the data from a centralized database. Node 1 is located at the company’s headquarters and includes data for all departments.
The data in the DEPARTMENT table is horizontally fragmented using the department number Dnumber. Since there are foreign key relationships in EMPLOYEE, PROJECT, and DEPT_LOCATIONS, they are also fragmented. This is a special type of fragmentation called derived fragmentation. These are easier to fragment since they have a direct foreign key relationship.
A more difficulty decision comes with the WORKS_ON table. It does not have an attribute that indicates which department each tuple belongs to. The authors choose to fragment based on the department that the employee works for. This is further fragmented based on the department that controls the projects that the employee is working on.
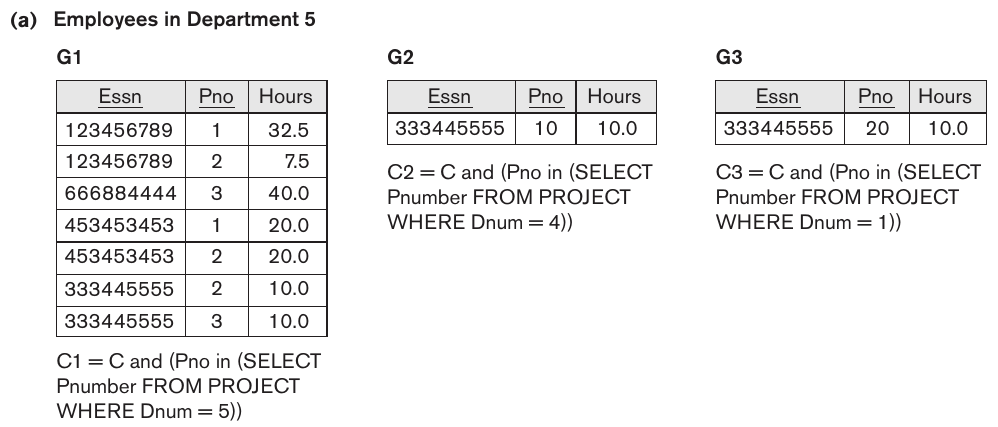
Figure 1: Fragmentation of WORKS_ON table for department 5. <@elmasri_fundamentals_2015>
In the figure above, all of the fragments include employees of the research department. The first fragment includes employees that work on projects controlled by the research department. The second fragment includes employees that work on projects controlled by the administration department. The third fragment includes employees that work on projects controlled by headquarters.
Data Concurrency
Distributed systems that employ data replication or allow for multiple users to access the same data at the same time need to be concerned with data concurrency. This is the process of ensuring that the data remains consistent when multiple users are accessing the same data at the same time. Several problems can occur in a DDBMS, such as
- inconsistency between multiple copies of the data,
- failure of a node,
- network outages that sever the connection between nodes,
- failure of a transaction that is applied to multiple nodes,
- and deadlocks between transactions.
Concurrency Control
Many control solutions for distributed systems are based on the idea of a centralized locking authority. This authority is responsible for granting locks to transactions that request them. The authority is also responsible for granting access to data that is locked by other transactions. When an object is locked, it cannot be accessed by other transactions.
In this case, the central authority may be a distinguished copy of the data. All requests to lock or unlock are sent to that copy.
Primary Site Technique
All locks are kept at a primary site. This site is responsible for granting locks to transactions that request them. The primary site is also responsible for granting access to data that is locked by other transactions. This is a simple technique that is easy to implement. However, it is not very scalable since all requests must go through the primary site. Note that this does not prevent transactions with read locks from accessing any copy of the item. If a transaction has a write lock, the primary site must update all copies of the data before releasing the lock.
Primary Site with Backup
If the primary site fails in the first approach, the system effectively becomes unavailable. To prevent this, we can have a backup primary site that takes over if the primary site fails. This is a simple solution that is easy to implement. If the primary site fails in this case, a backup takes over and becomes the new primary. A new backup is chosen so that the system can continue to operate. One downside to this approach is that locks must be recorded at both the primary and backup sites.
Primary Copy Technique
Lock coordination is distributed among various sites. Distinguished copies for different items are distributed to different sites. A failure at one site would only affect the transactions that are accessing its distinguished copies. Other items not on the site would remain functional. In the case of a failure, the sites that are still running can choose a new coordinator based on some strategy. One such strategy is to have all running sites vote on a new coordinator. The site with the most votes becomes the new coordinator.