Instance Segmentation
- Introduction
- Mask R-CNN (He et al. 2018)
- CenterMask (Lee and Park 2020)
- Cascade R-CNN (Cai and Vasconcelos 2019)
- MaskFormer (Cheng, Schwing, and Kirillov 2021)
- Mask2Former (Cheng et al. 2022)
- Mask-FrozenDETR (Liang and Yuan 2023)
- Segment Anything (Kirillov et al. 2023)
- Segment Anything 2 (Ravi et al. 2024)
Introduction
Instance segmentation is the task of assigning a label to pixels based on which class they belong to. In a supervised setting, the results are more focused given that the domain objects is well defined. Remember that in Image Segmentation, the pixels were grouped under a general critera such as proximity or color.
Mask R-CNN (He et al. 2018)
Mask R-CNN adapts Faster R-CNN to include a branch for instance segmentation (Ren et al. 2017). This branch predicts a binary mask for each RoI, and the training loss is updated to include this branch.
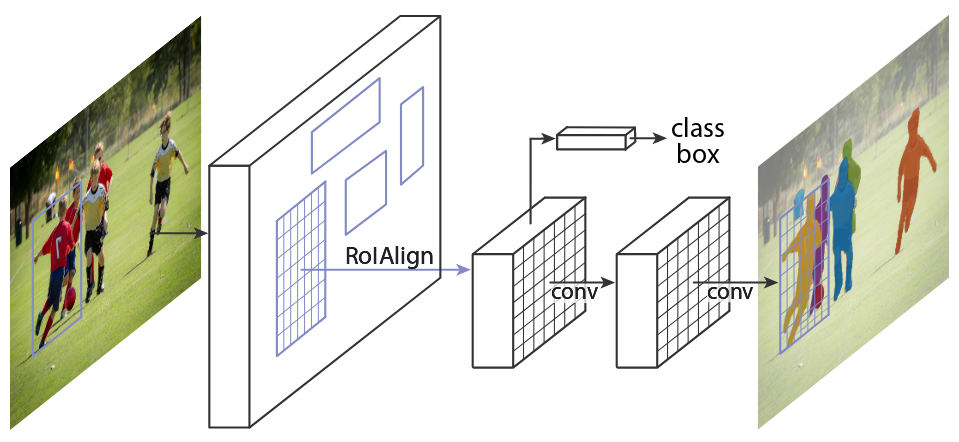
Figure 1: Mask R-CNN framework (He et al. 2018).
Key Contributions
- Introduces RoIAlign to preserve exact spatial locations.
- Decouples mask and class predictions, allowing the network to generate masks for each class without competition among classes.
- Achieved SOTA reults on COCO instance segmentation, object detection, and human pose estimation.
RoIAlign
Transforming a spatial-preserving representation into a compressed output necessarily removes that spatial encoding. In other words, the spatial information is lost when the feature map is downsampled. To address this, Mask R-CNN introduces RoIAlign, which preserves the spatial information of the feature map. RoIAlign is a bilinear interpolation method that samples the feature map at the exact locations of the RoI.
Regions of Interest (RoIs) are generated based on the output feature map of the backbone network. These bounding boxes do not line up perfectly with the feature map. RoIPooling would round the coordinates to the nearest integer, which can lead to misalignment. This was not an issue in Faster R-CNN, where the goal was to predict the class and bounding box. However, for instance segmentation, the spatial information is crucial.
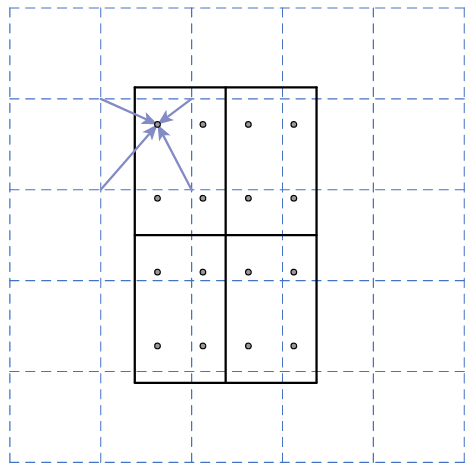
Figure 2: RoIAlign. Dashed grid - feature map, solid grid - RoI (He et al. 2018).
As seen in the figure above, RoIAlign computes the exact values of the feature map at regularly sampled locations in teach RoI bin. The sampled points in each bin are aggregated via max or average pooling. The output is still the same size as the RoI, but it takes data from the feature map at the exact locations of the RoI.
Mask Head
Given the feature map produce by RoIAlign, the mask network head is a small convolutional network that upsamples the feature map using a series of convolutions and deconvolutions. The output is a binary mask for each RoI. Not only does the mask head serve to decouple the mask prediction from box and class prediction, but it also allows the network to learn features specific to mask generation.
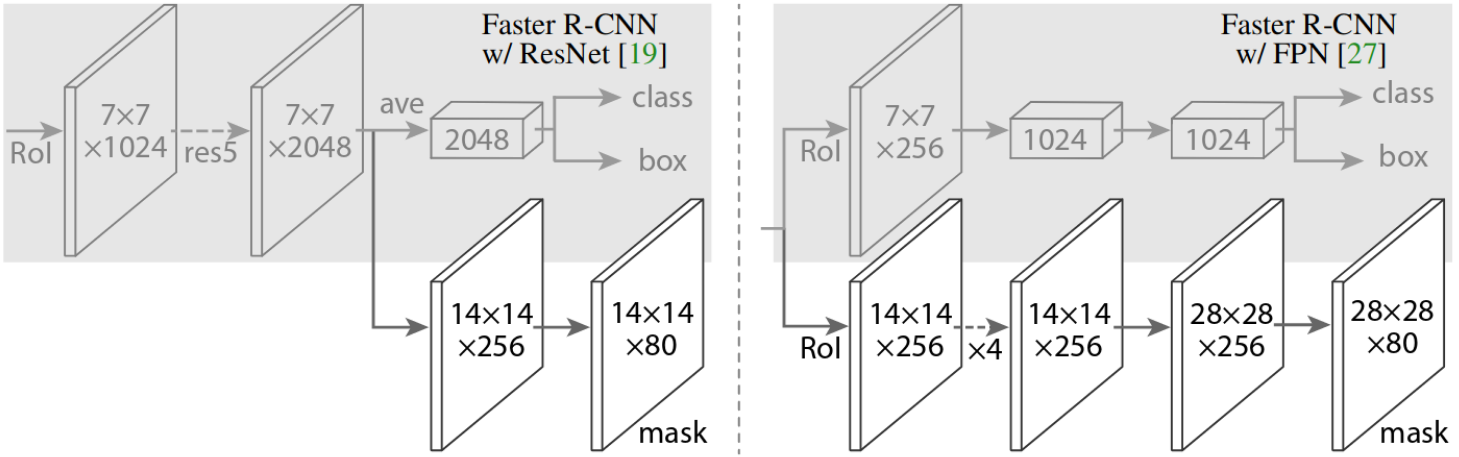
Figure 3: Head Architecture (He et al. 2018).
Results
Mask R-CNN achieved state-of-the-art results on the COCO dataset for instance segmentation, object detection, and human pose estimation. Using ResNeXt-101-FPN, Mask R-CNN achieved better performance over the leading models from the previous year’s competition, netting 37.1% AP on the COCO test-dev set.

Figure 4: Qualitative results versus FCIS (leading competitor) (He et al. 2018).
CenterMask (Lee and Park 2020)
CenterMask is a real-time anchor-free instance segmentation method. It adds a novel Spatial Attention-Guided Mask branch on top of the FCOS object detector.
Summary
- Anchor-free approach for bounding boxes.
- Spatial Attention-Guided Mask branch for instance segmentation.
- Two-stage architecture for object detection and mask prediction.
- Objects are represented by their center key points and bounding box sizes.
- Outperforms Mask R-CNN on common benchmarks.
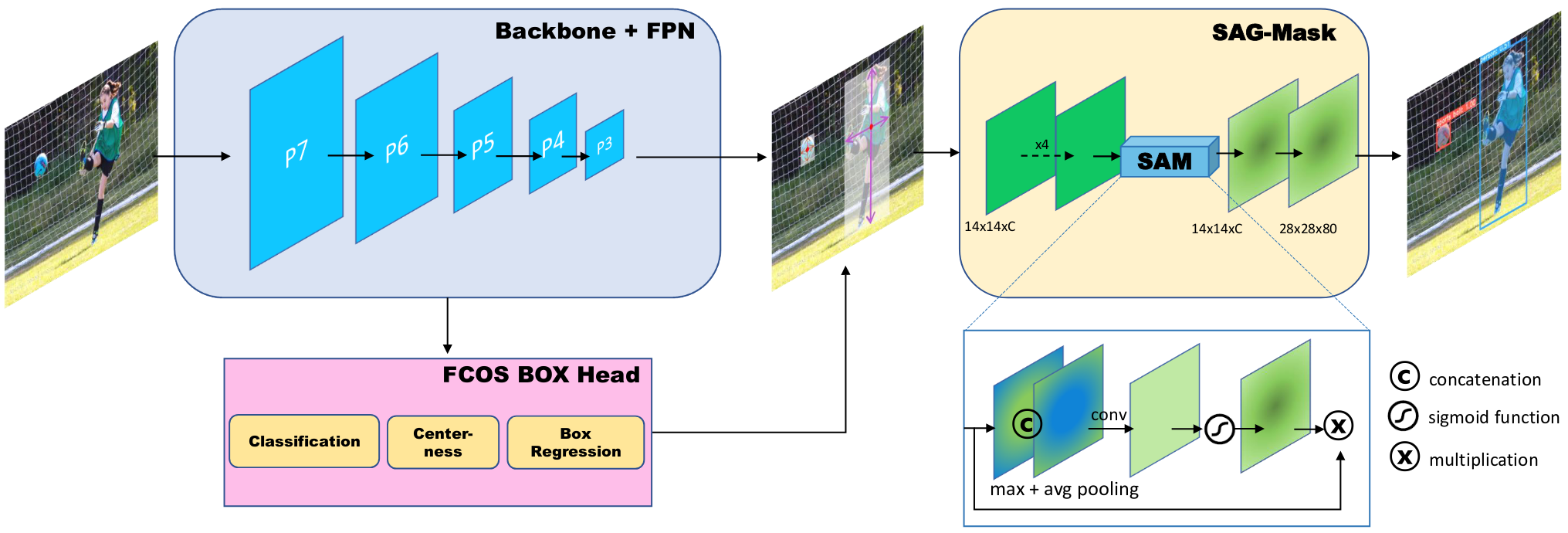
Figure 5: Architecture of CenterMask (Lee and Park 2020).
Backbone
The authors adapt VoVNet (Variety of View), a CNN-based architecture, as the backbone network. VoVNet is designed to capture multi-scale features and has a high computational efficiency. VoVNet2 adds a spatial attention module to the original VoVNet architecture along with residual connections.
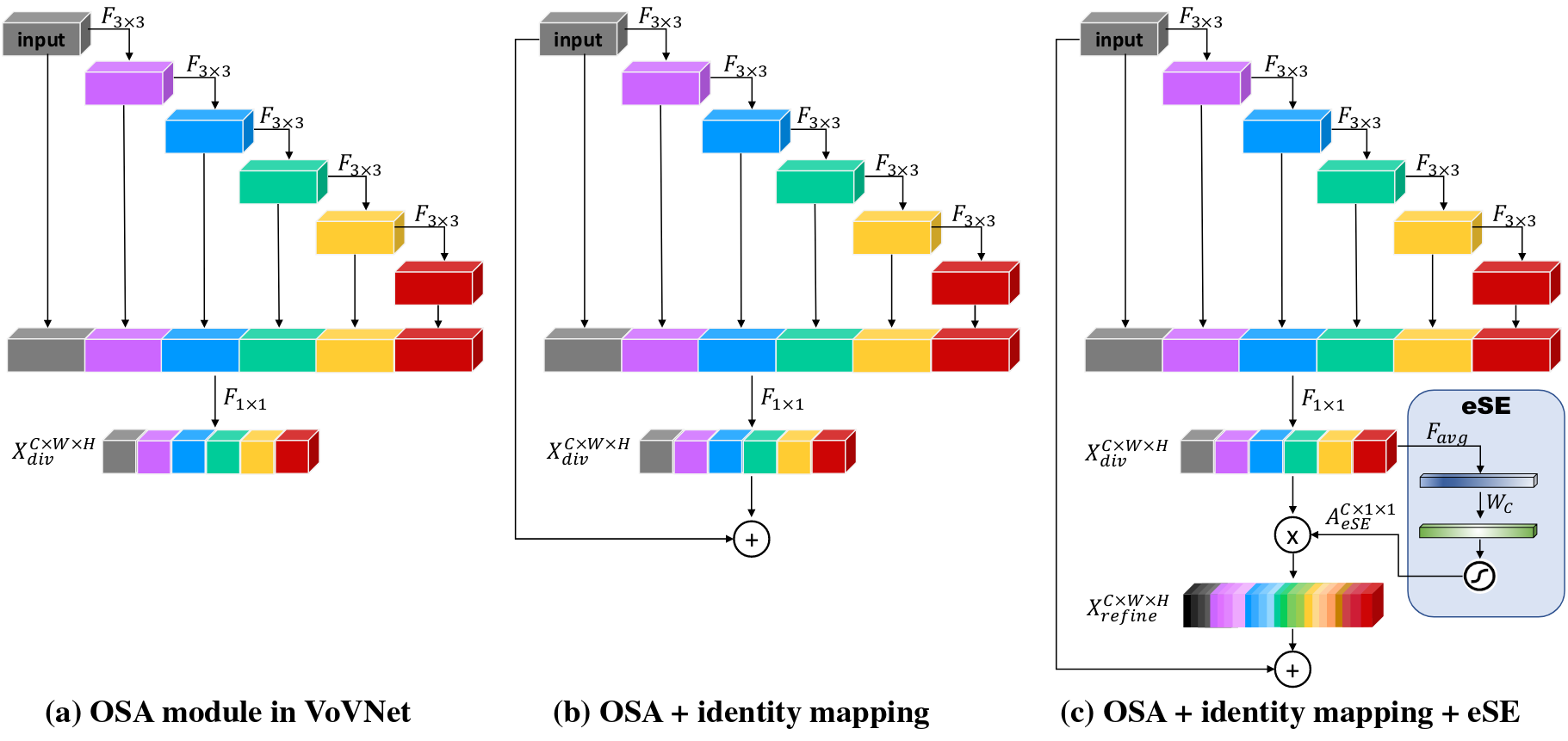
Figure 6: VoVNet2 Backbone comparison (Lee and Park 2020).
The residual connections were added to the original VoVNet architecture to improve the gradient flow during training. In the original network, performance degradation occurred when stacking multile One-Shot Aggregation (OSA) blocks. The OSA blocks are designed to capture multi-scale features by aggregating information from different scales via successive convolutions. The features are concatenated and passed through a bottleneck layer to reduce the number of channels.
The effective Squeeze-Excitation layer takes the concatenated features and applies a global average pooling operation per channel. The produces a \(1 \times 1 \times C\) tensor, where \(C\) is the number of channels. This is passed through a fully connected layer with a sigmoid function to produce a channel-wise attention map. The attention map is then multiplied with the input features to produce the final output. This allows the network to focus on the most important features.
Feature Pyramid Networks (Lin et al. 2017)
The output of the backbone network is passed through a Feature Pyramid Network (FPN) to extract multi-scale features. The FPN is a top-down architecture with lateral connections that allow the network to capture features at different scales. Since multiple scales are produced, RoIAlign must be adapted to handle them.
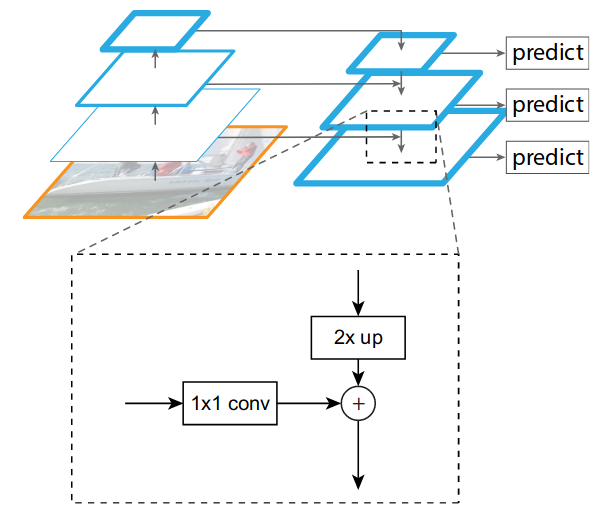
Figure 7: FPN Architecture (Lin et al. 2017).
Scale-adaptive RoI Assignment
The output of the backbone + FPN is a series of feature maps at different scales. The authors propose a scale-adaptive RoI assignment method to assign RoIs to the appropriate feature map. This is done by calculating the area of the RoI and assigning it to the feature map that best matches the RoI size. This allows the network to focus on the most relevant features for each object. Given the appropriate feature map, RoIAlign is used to extract the features for each RoI.
FCOS Detection Head
FCOS is a region proposal network that predicts bounding boxes and class labels without using predefined anchor boxes. Object detection is treated as a dense, per-pixel prediction task. The predicted bounding boxes are used to crop the feature map, which is then passed to the mask branch.
Summary
- Uses a CNN with a Feature Pyramid Network to extract multi-scale features. In this case, the VoVNet2 backbone is used.
- Predicts a 4D vector plus a class label at each spatial location of a feature map.
- Predicts deviation of a pixel from the center of its bounding box.
SAG-Mask Branch
The Spatial Attention-Guided Mask branch highlights meaningful pixels while suppressing irrelevant ones via spatial attention. The input to this branch are the features extracted from RoI Align. These come from the backbone + FPN module.
The feature maps go through a round of 4 convolutional layers for further feature processing. The SAM module itself generates average and max-pooled features along the channel axis: \(P_{avg},\ P_{max} \in \mathbb{R}^{1 \times W \times H}\). These are concatenated and processed through another convolutional layer with a sigmoid activation function.
\[ A_{sag}(X_i) = \sigma(F_{3 \times 3}(P_{max} \circ P_{avg})) \]
The sigmoid ensures that each output value represents how much attention should be paid to the original input features. This is then multiplied element-wise with the original output, resuling in an attention-guided feature map.
\[ X_{sag} = A_{sag}(X_i) \otimes X_i \]
Results
CenterMask achieved 40.6% mask AP (over all thresholds) using their base model, a 1.3% improvement over Mask R-CNN. They also achieved 41.8% when built using Detectron2. However, Detectron2 was released after their original submission, so the results are not official.
Cascade R-CNN (Cai and Vasconcelos 2019)
This paper addresses two key problems with high-quality detections.
-
Overfitting due to vanishing positive samples for large thresholds.
When training object detectors, the IoU threshold is used to determine whether a detection is a positive or negative sample. A higher IoU is a stricter criteria for what constitutes a positive sample. As this threshold increases, the number of positive samples decreases since it is more challenging for the model to detect. Typically, the proposals are selected as positive examples during training if they have at least 0.5 IoU. Raising that threshold means that the model sees fewer positive samples, leading to overfitting.
-
Inference-time quality mismatch between detector and test hypotheses.
Training deals with lower quality samples (IoU ~0.5), but test samples include a range of low and high quality samples. This can lead to poor performance during inference.
Summary
- Uses an RPN as in Faster R-CNN.
- Performs iterative refinements to bounding box predictions using multi-stage detection.
- Achieves SOTA performance for object detection (50.9% AP) and instance segmentation (42.3% AP).
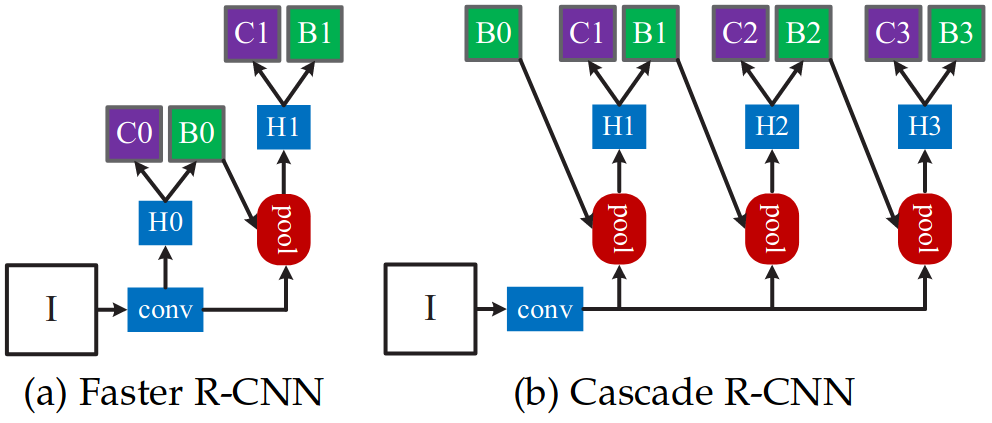
Figure 8: Comparison of architectures (Cai and Vasconcelos 2019).
Multi-Stage Detection Heads
Multi-stage detection allows the model to progressively refine bounding box predictions. This allows the model to train with both low and high quality samples, alleviating the problems of overfitting and quality mismatch.
Initial Detection
The method begins similarly to Faster R-CNN. A RPN generates the initial proposals which are processed by the first detection stage. The output is a set of refined bounding boxes along with object labels and confidence scores. The first stage follows previous convention and sets the IoU of positive samples to 0.5. That is, positive samples are labeled as such in training if they have >= 0.5 IoU with the ground truth.
Progressive Refinement
Each stage after that uses the output bounding boxes from the previous stage as input. The IoU is increased during training in subsequent stages to focus on higher quality detections. For example, if stage one trains on 0.5 IoU, then stage two will take those bounding boxes and select positive samples with 0.6 IoU, and so on.
Cascade Mask R-CNN

Figure 9: Original Mask R-CNN (left) and three different Cascade Mask R-CNN strategies (right) (Cai and Vasconcelos 2019).
To adapt the model for instance segmentation, the segmentation branch is inserted in parallel to the detection branch. The main question during development was where to add the segmentation branch and how many should be added. The authors try several different configurations, as seen in the figure above. Experimentally, the third (right-most) strategy depicted above yields the greatest performance of 35.5% AP.