MapReduce
These are my personal notes from the book Fundamentals of Database Systems by (Elmasri and Navathe 2015). I highly recommend reading the original source material. The contents of the article should only serve as a brief overview of the topic.
What is MapReduce?
MapReduce is a programming model for processing large datasets in parallel. It was originally developed by Jeffrey Dean and Sanjay Ghemawat at Google in 2004 (Dean and Ghemawat 2008). It is based on the functional programming paradigm and is inspired by the map and reduce functions in Lisp and other functional languages. The MapReduce programming model is implemented in the Hadoop framework.
Hadoop is made up of
- Hadoop Distributed File System (HDFS)
- Yet Another Resource Negotiator (YARN)
- MapReduce
- Hadoop Common
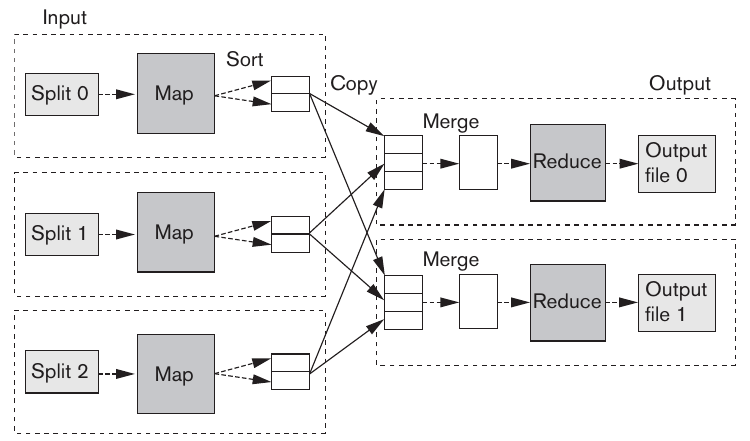
Figure 1: Diagram of MapReduce execution (Elmasri and Navathe).
Example: Word Count
The classic introductory example for MapReduce is word count, as described in (Dean and Ghemawat 2008). Let’s say we have a collection of text documents that we want to preprocess for a Natural Language Processing pipeline. One of the first steps is to count the number of times each word appears in the corpus. This is a simple task that can be done in a single machine, but let’s assume that the corpus is too large to fit in memory on a single machine. We can use MapReduce to distribute the work across multiple machines.
The problem is split into two steps: map and reduce. Each step is represented as a function that can run on any arbitrary number of nodes. For now, we will not worry about how the original data is split up efficiently. Instead, assume that each machine gets a single document.
def map(doc):
for word in doc:
emit(word, 1)
def reduce(word, counts):
emit(word, sum(counts))
The map function takes a document and emits a key-value pair for each word in the document. The key is the word and the value is 1. The reduce function takes a word and a list of counts and emits a key-value pair with the word and the sum of the counts. The output of the map function is a list of key-value pairs that are grouped by key. The reduce function is then applied to each group of key-value pairs.
Hadoop Distributed File System (HDFS)
Store metadata and application data on different nodes. Metadata is stored on the NameNode. Application data is stored on DataNodes. This data is replicated across multiple DataNodes. HDFS uses primary-secondary architecture. The NameNode is the primary and the DataNodes are the secondaries. DataNodes are typically partitioned into 1 node per machine. NameNodes maintain inodes about file and directories. These inodes are used to map file blocks to DataNodes. NameNodes instruct the DataNodes to create, delete, and replicate blocks. Data is retrieved by contacting the NameNode to get the block locations and then contacting the DataNodes directly.
NameNode
Maintain an image of the file system. Maintain a journal of changes to the file system.
Secondary NameNodes are used to create checkpoints of the NameNode’s state.
DataNode
Periodically send heartbeats to the NameNode to indicate their current state (BlockReport). Block locations are not part of the namespace image. BlockReports are used by services like the MapReduce JobTracker to determine where to schedule tasks.
File I/O Operations
HDFS is single-writer, multiple-reader. A file consists of blocks. Data that is written on the last block becomes available after an hflush operation.
MapReduce Overview
MapReduce is also a primary-secondary architecture. The JobTracker is the primary process and the TaskTrackers are the secondaries.
JobTracker
Manages life cycles of jobs and schedules tasks on the cluster.
Job Submission
- Gets a new ID from the job tracker.
- Verifies output specifications.
- Computes input splits for the job.
- Copies any resources needed to run the job.
- Informs the job tracker that it is ready for execution.
Job Initialization
When a job is initialized, it is placed in a queue with all information related to executing and tracking the job. A map task is created for each of the input splits. Further, a job setup and cleanup task are created.
Task Assignment
Each TaskTracker periodically sends a heartbeat to the JobTracker with status updates. These inform the JobTracker that it is alive or is able to run a new task. When a TaskTracker is ready to run a new task, the JobTracker will allocate a new one by selecting it using some defined scheduler. There is a default scheduler that will pick based on priority, but a custom scheduler can be given to the job.
Another consideration for assigning is a map task is data locality. Map tasks are based on the input splits, so the JobTracker will try to run the task on the same node that the data is located. If this is not possible, it will prioritize based on the distance between the node and the data. For reduce tasks, there are no locality considerations.
Task Execution
When a task is executed, any pertinent information is copied from the shared filesystem to a local filesystem. A JVM is launched to run each task so that any errors will only affect the JVM and not the entire TaskTracker. The JVM will run the task and then report back to the JobTracker with status updates.
Job Completion
A job is completed once the last task is finished. In this case, a job cleanup task is run to clean up any resources used by the job.
TaskTracker
TaskTrackers run one per worker node on a cluster. Both map and reduce tasks run on Worker nodes. When a TaskTracker is started, it registers with the JobTracker so that the JobTracker can assign tasks to it. The actual task is run in a separate process on the Worker node which is managed by the TaskTracker.
Fault Tolerance
In Hadoop v1, three types of failures must be considered. The first two are the TaskTracker and JobTracker. The third is the spawned process that runs the task on the TaskTracker.
Task Failure
Tasks can fail due to bad input, faulty code, hardware failure, or some other run time error. When an individual task fails, the error is logged and the failure is reported back to the parent TaskTracker. Since the TaskTracker is still running, it can notify the JobTracker that it is free to run another task.
There is also a default timeout duration for tasks that are not making progress. If a task exceeds this timeout, it is killed and the TaskTracker is notified. The default timeout is 10 minutes but can be configured by the user. There are also settings dictating how many times a task can fail before the job is considered failed or the percentage of tasks that can fail before the job is considered failed. There may be circumstances in which task failures are acceptable as long as some of the work is completed.
TaskTracker Failure
TaskTrackers that fail or are unresponsive past the heartbeat timeout are considered dead. The JobTracker will remove it from its pool of trackers to schedule tasks on. Tasks that were completed or in progress on the failed TaskTracker are rescheduled since the intermediate data is no longer available.
TaskTrackers that fail repeatedly are added to a blacklist and are not used for scheduling tasks. This can occur if the TaskTracker is not configured correctly or if the TaskTracker is running on faulty hardware.
JobTracker Failure
The JobTracker is a single point of failure in Hadoop v1. If the JobTracker fails, all jobs that are running or waiting to run are lost. The rate of failure is typically low since the chance that a single machine fails is low. If it does fail, a restart is attempted and all running jobs need to be restarted.
Shuffle and Sort
The shuffle and sort phase is a key process which defines how data is moved from the map tasks to the reduce tasks. Data may be split among many map tasks, but reducers get all rows for a given key together. The shuffle and sort phase is responsible for this. It is split up into three phases.
Map Phase
Output from the map tasks is stored in memory in a circular buffer. Once that buffer becomes full, it spills over to the disk. Before going to the disk, it is partitioned based on the reducer that it will ultimately be sent to. This acts as a sort of pre-sorting to optimize the shuffle and sort phase.
Depending on the setting for the size of spill files, the map phase may produce multiple spill files. These files are merged into a single file before being sent to the reducers. The final result is a single file per reducer that is sorted by key.
Copy Phase
The data needed by a particular reducer task is split up among many map tasks. The copy phase is responsible for copying the data from the map tasks to the reducer tasks. The reducer will begin copying as data is made available by the map tasks, even if all map tasks have not been completed.
Copies can be executed in parallel via threading. The JobTracker is responsible for assigning the reducers to the map tasks so that the data is copied to the correct reducer. When all map tasks have completed, the reducer will begin the reduce phase.
Reduce Phase
In this phase, data is merged while maintaining their sorted order. The reduce function is this executed for each key in the sorted output. The output is written directly to the output filesystem, which is commonly HDFS.
Types of Schedulers
Early versions of Hadoop used a simple FIFO scheduler. This scheduler would run jobs in the order that they were submitted. This is not ideal since it does not take into account the size of the job or the priority of the job. A job that is submitted after a large job will have to wait until the large job is completed. Considering longer running jobs like machine learning training, a better scheduler is needed.
The Fair Scheduler
The fair scheduler aims to give every user an equal amount of cluster capacity over time. This allows multiple jobs to be running simultaneously. The scheduler does this by placing jobs in pools assigned to each user. This allows short jobs to run without waiting for long jobs to complete.
The fair scheduler also supports preemption. This allows the scheduler to kill tasks that are running for too long to make room for other jobs. This is useful for long running jobs that are not making progress. Note that this does not kill the entire job. The tasks that are killed are rescheduled on other TaskTrackers.
The Capacity Scheduler
In capacity scheduling, a cluster is divided into multiple queues. Each queue is assigned some amount of cluster capacity. These queues are hierarchical, so a queue can be assigned to a user or a group of users. This allows for more fine grained control over the cluster capacity. In effect, this allows for multiple clusters to be managed by a single cluster.
Merging Database Functions and MapReduce
The power of MapReduce was apparent, but all operations had to be framed in the context of a mapping and reduce functions. This made it difficult or tedious to perform common database operations. Several projects were started to bridge the gap between MapReduce and databases.
Apache Pig
Developed by Yahoo, Pig Latin is a high level language that glues together SQL and MapReduce. It was not meant to replace SQL. In fact, the authors note that people in data analysis fine SQL to be unnatural for data analysis. Their work was mean to provide something that meets the declarative style of SQL and procedural style of MapReduce. Consider their opening example.
Given a table of urls: (url, category, pagerank), find the average pagerank of high-pagerank urls in that category. In SQL, a query might look like this.
SELECT category, AV G(pagerank)
FROM urls
WHERE pagerank > 5
GROUP BY category
HAVING COUNT(*) > 10**6
An equivalent query in Pig Latin would look like this.
good_urls = FILTER urls BY pagerank > 0.2;
groups = GROUP good_urls BY category;
big_groups = FILTER groups BY COUNT(good_urls) > 10**6;
output = FOREACH big_groups GENERATE category, AVG(good_urls.pagerank);
Each statement in Pig Latin describes a data transformation. These statements are converted into an ensemble of MapReduce jobs, but each statement is not necessarily a single MapReduce job. The Pig Latin compiler is responsible for optimizing the statements.
Apache Hive
Hive was developed at Facebook to provide an SQL-like interface for processing queries on big data. In addition to providing a high-level language, it also treats Hadoop like a DBMS. This allows users to impose structure on the data and query it using as if it were a traditional database.
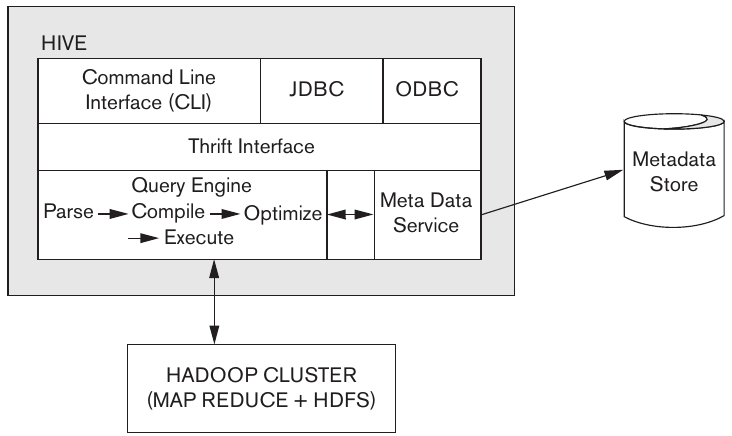
Figure 2: Hive Architecture (Elmasri and Navathe).
Hive comes with a query-based language called HiveQL that includes joints, aggregations, and other common SQL operations. The tables in Hive are linked directly to directories in HDFS. This allows for data to be loaded into Hive from HDFS and vice versa. Hive also supports partitioning and bucketing to improve performance. Bucketing stores the data physically in the same file, partitioned by the bucketing key.
Advantages of Hadoop/MapReduce
Consider scanning a 100 TB dataset using a single machine. At a rate of 50 Mbps, this would take around 24 days. Using 1000 machines in parallel would reduce this to about 30 minutes. The resources available can be scaled easily by adding more machines to the cluster. In the event that a machine fails, the tasks can be reassigned to other machines without losing the job completely.
Hadoop v2 AKA YARN
Hadoop v1 was well received and solved many of the problems efficiently through its MapReduce programming model. However, many problems arise naturally as the size of the cluster grows.
- The JobTracker is a single point of failure. As the cluster size increases, this becomes more of an issue.
- Resources are allocated statically, resulting in a large amount of unused compute when processing jobs.
- Not every job fits cleanly into the MapReduce programming model.
In addition to these issues, YARN aims to improve scalability, resource utilization, and flexibility. By increasing the availability of nodes at any given time, there are less wasted resources on a cluster. This is especially useful in enterprise-level clusters where there are many users and jobs running at any given time.
Supporting multiple programming models also aids to this scalability. Consider a machine learning model being trained for long periods of time. In Hadoop v1, developers would frame these as MapReduce jobs. A major problem with this is that after the original update, the jobs would exchange data outside of the purview of the JobTracker. This also means that the fault tolerance features built into Hadoop v1 were not available for these jobs.
Architecture
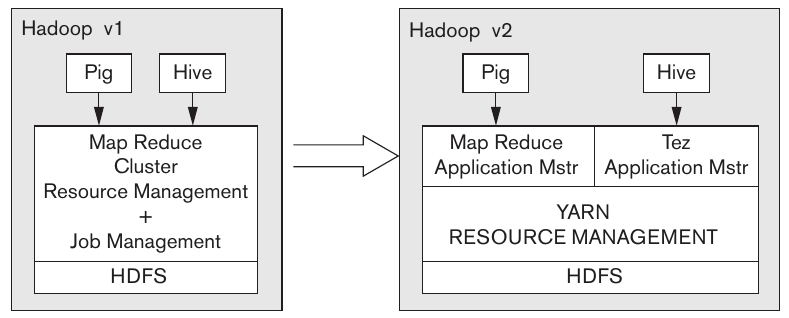
Figure 3: Hadoop v1 vs. YARN Architecture (Elmasri and Navathe).
ResourceManager
The ResourceManager is the master process in YARN. It is responsible for allocating resources to applications and scheduling tasks. Allocations are based on the chosen scheduler. ApplicationMasters will request resources from the ResourceManager. The ResourceManager will then allocate resources to the ApplicationMaster and notify the NodeManager to start the containers.
Since the ResourceManager is only responsible for scheduling the available resources, different applications can make use of the same cluster at the same time. This is a major improvement over Hadoop v1 where the JobTracker was responsible for scheduling all jobs.
NodeManager
The NodeManager runs on every worker node in the cluster. It launches and monitors containers on the node as well as reports the resource utilization back to the ResourceManager. It additionally provides services to Containers such as security, logging, and local file management.
ApplicationMaster
The ApplicationMaster manages the execution of an application’s processes. These applications can range from a traditional MapReduce job to a long-running machine learning model. The ApplicationMaster is responsible for negotiating resources with the ResourceManager and working with the NodeManager to execute and monitor the containers. It sends resource status updates to the ResourceManager as requirements change.
Container
A container is a collection of resources allocated to an application. These resources are allocated by the ResourceManager and managed by the NodeManager. These resources refer directly to the resources available on the node. This includes CPU, memory, disk, and network.
Fault Tolerance
The ResourceManager is a single point of failure in YARN. If it fails, it can restart and recover its state. Any containers in the cluster are killed and restarted. The ApplicationMaster is responsible for restarting any tasks that were running in the containers.
Execution Flow
The following gives an example of how a typical MapReduce job would be executed in YARN.
- The client submits a job to the ResourceManager.
- The ResourceManager allocates a container for the ApplicationMaster and launches the ApplicationMaster on a NodeManager.
- The ApplicationMaster negotiates resources with the ResourceManager.
- The ResourceManager allocates containers for the MapReduce tasks and launches them on the NodeManagers.
- The MapReduce tasks are executed in the containers.
- The ApplicationMaster monitors the MapReduce tasks and reports status updates to the ResourceManager.
- When the job is complete, the ApplicationMaster is unregistered and the containers are released.