NOSQL
NOSQL refers to Not Only SQL. A NOSQL system is commonly a distributed one that focuses on semi-structured data storage, high performance, availability, replication and scalability. These type of systems developed to meet the needs of large-scale internet applications where a traditional SQL database could not.
Consider an application like Amazon which manages a high volume of data and user requests. The application needs to be able to store and retrieve this data quickly and reliably. They created their own database system called DynamoDB which is a key-value store. DynamoDB has been used for many applications that require high performance and availability such as video streaming through services like Disney+.
The data that is used in these systems does not usually fit the mold of a traditional SQL database. For example, a relational database might store an object by disassembling it into its components and storing each component in a separate table. This is not ideal for a system that needs to store and retrieve data quickly. A NOSQL system will store the object as a whole and retrieve it as a whole.
NOSQL Characteristics for Distributed Systems
Given the nature of the applications that utilize NOSQL systems, the most important characteristic is high availability. Of course, performance is also important given the number of users that expect the service to remain responsive at all times.
Scalability
NOSQL systems typically aim for horizontal scalability. The applications that use these systems are expected to grow rapidly and the system needs to be able to handle the increased load. This sort of dynamic scaling means that implementations should not rely on a fixed number of nodes.
For example, during the holiday season, Amazon will need to rapidly scale up their infrastructure to handle the increased load. Cloud technologies are capable of doing this automatically, but the database system needs to be able to handle the increased load as well.
Availability
NOSQL systems are expected to be highly available. This means that the system should be able to handle failures and continue to operate. Data is typically replicated over multiple nodes. However, this replication comes with increased complexity for writing data. To deal with this, many NOSQL systems implement a relaxed version called eventual consistency.
Replication Models
There are two main replication models for NOSQL systems: primary-replica and primary-primary. In primary-replica replication, only one copy is the primary for which all write operations are applied. The write is propagated asynchronously to the replicas.
In primary-primary replication, all copies are equal and can accept write operations. This is more complex to implement, but it allows for better performance and availability. If multiple users write to the same object, the system needs to be able to handle the conflict through a reconciliation process.
Sharding
Depending on the application, a NOSQL collection could have millions of documents. These may need to be accessed simultaneously by a large number fo users. Sharding is a technique that allows the data to be distributed across multiple nodes. In this way, multiple nodes can work in parallel to handle the load. This has an added benefit of ensuring that no single node is overloaded.
High-Performance Data Access
In a distributed system with millions upon millions of objects distributed across many nodes, how do you find the object you are looking for? NOSQL systems typically use a hash-based approach to find the object. This is done by hashing the key of the object and using the hash to determine which node the object is stored on. This is a very fast operation and allows for the system to scale to millions of objects.
Another solution is called range partitioning in which the location is determined based on a range of key values. Each node would handle a different partition of the keys.
Other Characteristics
NOSQL systems do not require a schema. This means that the data does not need to be structured in a specific way. This is useful for applications that need to store a variety of data types. For example, a social media application might need to store user profiles, posts, comments, etc. These are all different types of data that would not fit well into a relational database. Instead of a schema, a language for describing the data is used. A common language is JSON.
Given the common application of NOSQL systems, a complex query language is not required. Many of the requests are in the form of a simple read or write operation. This allows for the system to be optimized for these operations. These operations are typically provided by an API and are called CRUD operations (Create, Read, Update, and Delete). Without the full power of SQL, complex operations such as JOIN or CONSTRAINTS must be handled by the application.
NOSQL Data Models
There are four main data models used by NOSQL systems: key-value, column, document, and graph. Each of these models has its own advantages and disadvantages. The model that is chosen depends on the application and the type of data that is being stored.
Key-Value
The key-value model is the simplest of the four. It is essentially a hash table where the key is used to retrieve the value. The value can be any type of data. This model is very fast and can scale to millions of objects.
Column
Tables are partitioned by columns into column families. Each column family is stored in its own files.
Document
Documents are stored in collections. Each document is stored as a JSON object. This model is very flexible and can store a variety of data types. It is also very fast and can scale to millions of objects. The documents are typically queried using their document ID, but other indices can be created to speed up queries.
Graph
Graphs are used to represent relationships between objects. Each object is represented as a node and the relationships are represented as edges. This model is useful for applications that need to represent complex relationships between objects.
CAP Theorem
The CAP theorem states that a distributed system can only guarantee two of the following three properties: consistency, availability, and partition tolerance. Consistency means that all nodes see the same data at the same time. Availability means that every request receives a response. Partition tolerance means that the system continues to operate despite network failures.
Document-Based NOSQL Systems
In document-based NOSQL systems, the data is self-describing as there is no need for a schema. These sytems store documents which are essentially JSON objects. The documents are stored in collections which are similar to tables in a relational database. The documents are retrieved using their document ID.
MongoDB
MongoDB is a document-based NOSQL database that is flexibile, scalable, and high-performance. It stores data in a JSON-like format called BSON (Binary JSON). Inidividual documents are stored in a collection. No schema is needed to begin storing data. The python code below will create a new collection for our RPG Users with a simple command in pymongo:
db['users']
This will create a new collection named users with the default settings. If you want to specify additional options, call the create_collection function. Common parameters include determining of a collection is capped by the storage size and maximum number of documents.
Representing Data
Whenever a new item is inserted to a colletion, a unique ObjectId is created and indexed. If the ID of a document should match a user-defined protocol, it can be set manually. Since there is no schema to specify a relationship, document relationships can be created by including the ObjectIds of objects you wish to reference in your data.
There are multiple ways to represent relationships between documents. Consider a Character that holds multiple items in an Inventory. The items could be referenced as an array of Item objects within the Character object itself. Alternatively, the Character could hold an array of ObjectId~s that reference the ~Item objects in the Inventory collection. A third approach would have each Item reference the Character that owns it. The best approach depends on the application and the type of queries that will be performed.
CRUD Operations
CRUD stands for Create, Read, Update, and Delete. Single or multiple documents can be implemented with the insert function. In pymongo, you can use either Collections.insert_one or Collections.insert_many. The insert_one function takes a single document as an argument and returns the ObjectId of the inserted document. The insert_many function takes a list of documents as an argument and returns a list of ObjectIds.
db['users'].insert_one({'name': 'Naomi', 'age': 25})
db['users'].insert_many([{'name': 'Naomi', 'age': 25}, {'name': 'James', 'age': 30}])
Reading objects is done with the find function. There are several variants of this available in pymongo.
find_onereturns a single document that matches the query.findreturns a cursor that can be iterated over to retrieve all documents that match the query.find_one_and_deletereturns a single document that matches the query and deletes it.find_one_and_replacereturns a single document that matches the query and replaces it with the specified document.find_one_and_updatereturns a single document that matches the query and updates it with the specified document.
val = db['users'].find_one({'name': 'Naomi'})
# Print the document
print(val)
# Print the name
print(val['name'])
Updating documents is done with the update function. We saw an updated combined with find above, but pymongo also implements update_one and update_many. The update_one function takes a query and an update document as arguments. The update_many function takes a query and an update document as arguments. Both functions return a UpdateResult object that contains information about the operation.
db['users'].update_one({'name': 'Naomi'}, {'$set': {'age': 26}})
Deleting documents is done with the delete_one and delete_many functions. Both functions take a query as an argument and return a DeleteResult object that contains information about the operation.
db['users'].delete_one({'name': 'Naomi'})
Characteristics
MongoDB uses a two-phase commit method to ensure transaction atomicity and consistency. In the first phase of the process, a coordinator sends a message to all nodes to prepare for the transaction. Each node then responds with an acknowledgement. If all nodes respond with an acknowledgement, the coordinator sends a commit message to all nodes. If any node fails to respond with an acknowledgement, the coordinator sends a message to roll back the transaction.
For data replication, a variation on the primary-replica model is used. A primary node is chosen with at least one replica. More nodes can be added at the cost of increased time for writes. The total number of nodes for a replica set is at least 3, so if only a primary and one replica are used, an arbiter must be chosen to break ties. In fact, any replica set with an even number of nodes must have an arbiter.
All write operations mus be performed on the primary copy before being propagated to the replicas. Users can determine the read preference for their application. The default is to read from the primary copy, but users can choose to read from the nearest copy or a specific copy. If a copy other than the primary is chosen for the read preference, it is not guaranteed that the user will get the lastest version of the data.
Sharding
We previously discussed that having all of the data in a single collection can lead to performance issues. Sharding is a technique that allows the data to be distributed across multiple nodes. This allows for multiple nodes to work in parallel to handle the load. Sharding splits the data into disjoint partitions which can then be stored on different nodes.
The partitions can be determined via hash partitioning or range partitioning. In either case, a document field must be chosen to determine the partition. This partition field is called the shard key. It must exist in every document and be indexed.
When using sharding on MongoDB, a query router keeps tracks of which nodes contain which shards. The actual query is then routed to the node containing the shard. In the event that a query is sent to a node that does not contain the shard, the query router will forward the query to all nodes.
Key-Value NOSQL Systems
Key-value systems use a simple data model and typically do not have a query language. The data is stored as a key-value pair. The key is used to retrieve the value. The value can be any type of data. This model is very fast and can scale to millions of objects. Popular key-value stores include DynamoDB, Voldemort, Redis, and Cassandra. We will briefly discuss each of them below.
DynamoDB
DynamoDB was developed by Amazon to meet the needs of their large-scale internet applications. It is a key-value store that is highly available and scalable. It is also a managed service which means that Amazon handles the scaling and replication for you. It uses tables, items, and attributes without the need for a schema. The table itself holds multiple items which are self-describing. That is, the items have (attribute, value) pairs.
Tables must have primary keys which can be either a single attribute or pair of attributes. For single attributes, DynamoDB will build a hash index on this attribute. For pairs of attribute, a hash and range primary key is used. The primary key is the pair of attributes and the hash index is built on the first attribute. This allows for fast retrieval of items based on the first attribute. The second attribute can be used to sort the items for which the first attribute is the same.
Voldemort
Voldemort is a distributed key-value store based on DynamoDB and developed by LinkedIn and Microsoft. The distribution of data is handled via consistent hashing. Since Voldemort is based on DynamoDB, many of the characteristics described below also apply to DynamoDB.
Operations
Like DynamoDB, key-value pairs are the primary data structure. These are kept in a data store. Three basic operations are implemented: get, put, and delete. Data is stored as a byte array.
Formatted Data
Voldemort supports multiple formats for the data. The default format is a byte array, but other formats such as JSON and Protocol Buffers are supported. It provides default serializers for these formats, but users can also implement their own. As long as a Serializer class is implemented, it can be used to serialize and deserialize data.
Consistent Hashing
Voldemort distributes data based on a hash function that is applied to each key. The range of values on which the key is mapped corresponds to a node. The figure below shows an example of 7 regions being mapped to 3 nodes (Elmasri and Navathe 2015).
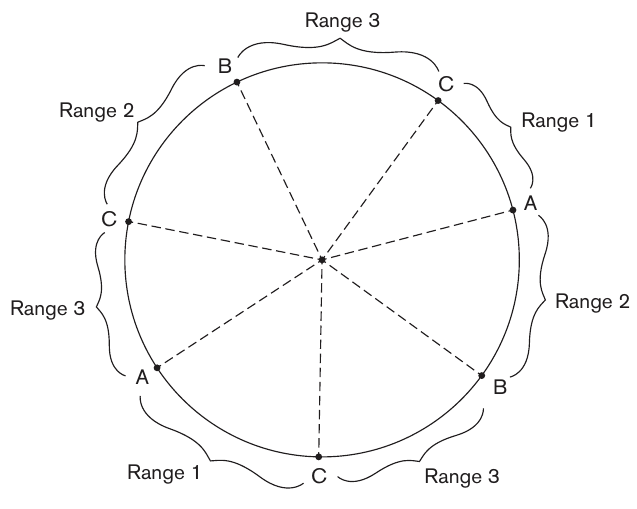
Figure 1: Consistent hashing in Voldemort.
Consistent hashing naturally permits data replication and horizontal scaling. As new nodes are added, only a small subset of the data needs to be rehashed to the new node. Replicas are created by mapping the key to multiple nodes.
Consistency
Concurrent writes are allowed which means there can exist multiple versions of the same key at different nodes. Consistency occurs when an item is read. If the system can reconcile the different versions of the key to a single value, it will pass that final value on. Otherwise, multiple versions may be sent to the application to be resolved.
Redis
Redis is an in-memory key-value store. This implies that is basic operations perform very quickly. However, it is not well suited for general purpose applications that require high volumes of data. A typical use-case for Redis would be caching, session management, or real-time analytics.
For example, Twitter uses Redis to drive their timeline feature. The posts are indexed using an ID and stored in Redis. When a user requests their timeline, the IDs are retrieved from Redis as a chain of IDs.
Cassandra
Cassandra can be used as a wide-column database (discussed below) or key-value database. It was originally developed at Facebook to handle large amounts of data across multiple commodity servers. It implements the Cassandra Query Language (CQL) which is similar to SQL. The data it partitioned similarly to other NOSQL datastores in that data is distributed in partitions across multiple nodes. CQL does not support cross-partition queries.
Column-Based NOSQL Systems
The largest differentiator of a column-based system and key-value system is the way the key is defined. A popular implementation of this type of system is known as BigTable which was developed by Google. It uses the Google File System (GFS) to store data. There is an open source equivalent named Apache Hbase which we will focus on below.
Hbase organizes data using namespaces, tables, column families, column qualifiers, columns, rows, and data cells. A column is identified by a family and qualifier. It can store multiple versions of the same data, differentiating each version using a timestamp. Each data cell is identified by a unique key. Tables are associated with column families. When loading data, the column qualifiers must be specified.
New column qualifiers can be created as needed, producing new rows of data. However, application developers must keep track of which qualifiers belnog to which family. This is a form of vertical partitioning. Since the columns belong to the same column family, they are stored in the same file.
Cells are reference by their key which is a combination of the row key, column family, column qualifier, and timestamp. For relational semantics, namespaces are used to define a collection of tables.
Hbase divides tables into regions which hold a range of row keys into the table. It is for this reason that they keys must be sortable lexicographically. Each region has a number of stores for which a column family is assigned. These regions of data are assigned to nodes in the cluster. To manage splitting and merging of regions, a primary server is used.
Graph-Based NOSQL Systems
The last category of NOSQL databases discussed in these notes are Graph Databases. These databases are used to represent relationships between objects. Each object is represented as a node and the relationships are represented as edges. This model is useful for applications that need to represent complex relationships between objects. A popular implementation of this type of system is known as Neo4j.
Nodes and relationships can have a unique collection of properties to describe them. Nodes are labeled, and nodes with the same label are grouped into collections for querying. Relationship types are useful for grouping relationships based on a common property.
Paths specify a traversal of a subgraph. They are used to specify a query and consist of nodes and relationships. The subgraph is used as a pattern to find other subgraphs that match the pattern. The query can be further refined by specifying constraints on the nodes and relationships.